


Optimizing Data Handling for Peptide Drug Discovery
Expanding teams, increasing data generation, and regulatory demands require companies to rethink their data management strategies. Developing innovative drugs requires customized solutions, as generic software often lacks the flexibility for specialized workflows. Companies need comprehensive data management systems that integrate with their existing tools and processes.
This case study examines how we provided such a solution for a clinical-stage U.S. biopharma startup focused on peptide drug development.
Data Management Challenges Throughout Drug Discovery
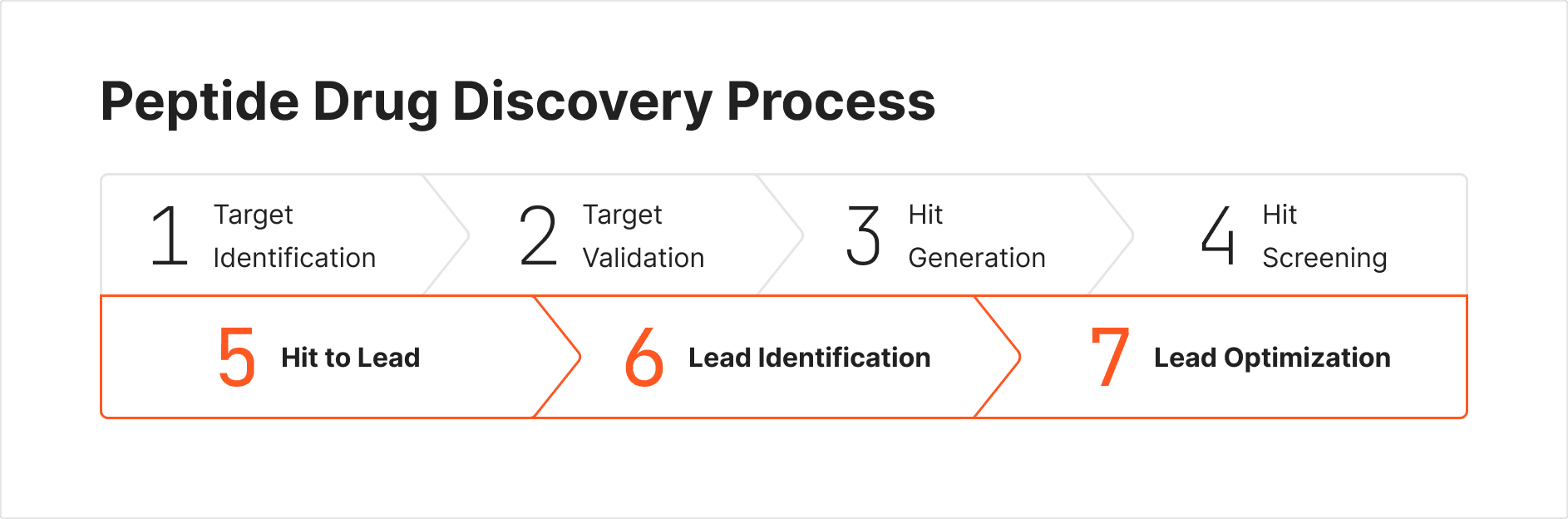
Image 1. Peptide Drug Discovery Process
The company faced several critical data management challenges throughout their drug discovery pipeline, particularly during the Hit-to-Lead stage. These were:
1. Manual Processes and Fragmented Tools: The company manually optimized and categorized peptide sequences using Excel spreadsheets. Although they used various tools for experiment management, modeling, and predictions, each step operated in isolation. They needed integration and automation to speed up the overall Hit-to-Lead process.
2. Data Inconsistency: Frequent manual entry errors in Excel spreadsheets, like incorrect formatting and extra spaces, led to data integrity issues. Without restricted input values or clear data entry rules, these problems affected statistical calculations and peptide synthesis.
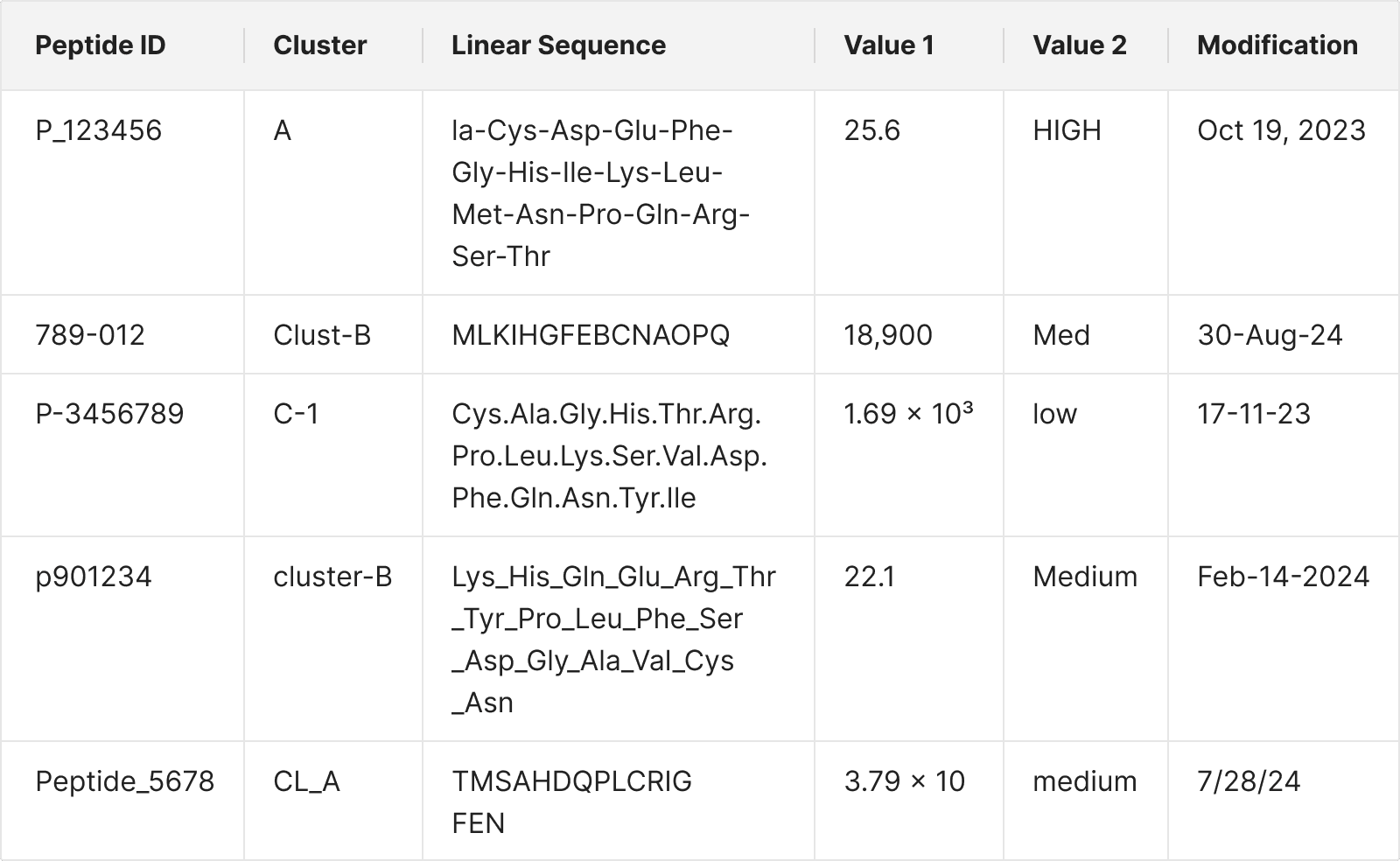
Image 2. Data Inconsistency Caused by Manual Entry Errors
3. Disorganized Data Storage: Company’s data was initially stored in scattered tables and local storage, making the management of large datasets difficult. Tracking information on amino acids, peptide monomers, and their characteristics became challenging. Employees created and updated multiple dictionaries without clear guidelines, which raised concerns about data trustworthiness. Using current and compatible synthesized monomers is crucial, as they directly affect peptide synthesis results.
Image 3. Disorganized Data Storages
4. Calculation Issues: Combining data from multiple spreadsheets created issues like formula adjustments and dependency management, which are prone to human error. Setting up validations in Excel to manage interdependencies was difficult. Moreover, uncontrolled use of copy/paste made it harder to keep data accurate. And accurate data is crucial for reliable peptide drug design calculations.
5. Data Interoperability Issues: Integrating data with other services was challenging due to the manual synchronization of Excel files, which was both time-consuming and prone to errors. This process hindered efficient data interoperability. Although Excel API integrations are sometimes used, they often lack the flexibility and speed of automated custom solutions. Additionally, finding experts skilled in these systems can be difficult.
6. Lack of Custom Features: Peptide design requires specialized features that Excel’s UI inherently does not support, further complicating the workflow.
7. Big Data Handling Issues: The company faced challenges in processing large peptide datasets, which often led to reduced application performance due to Excel’s limitations in efficiently handling millions of rows. They also expected difficulties with scalability as peptide dataset sizes grew.
8. Team Coordination Issues: Unclear data access rights and the inability to set different access levels made it difficult to manage sensitive information and protect confidential projects. The company struggled with process standardization and version control, making it difficult to track changes and maintain a single source of truth: very similar or duplicated peptides could be designed.
Quantori Solution
As a solution to these challenges, Quantori created a custom data management system for peptide drug design, specifically for the Hit-to-Lead stage. The system is a cloud-native, web-based single-page application built with Angular and TypeScript on the frontend, powered by a Python backend, and distributed across AWS infrastructure. It leverages Amazon Aurora's PostgreSQL
The main features were:
- Data Centralization (Addressing Data Inconsistency, Disorganized Storage and Big Data Handling): We implemented a structured approach to organize and centralize data about peptides, monomers, and their characteristics. Our solution includes standardized databases to ensure consistent data entry and formatting, with restricted input values to ensure data integrity. Changes are now tracked, ensuring that only the most current data is used. This approach also enables efficient handling of large datasets.
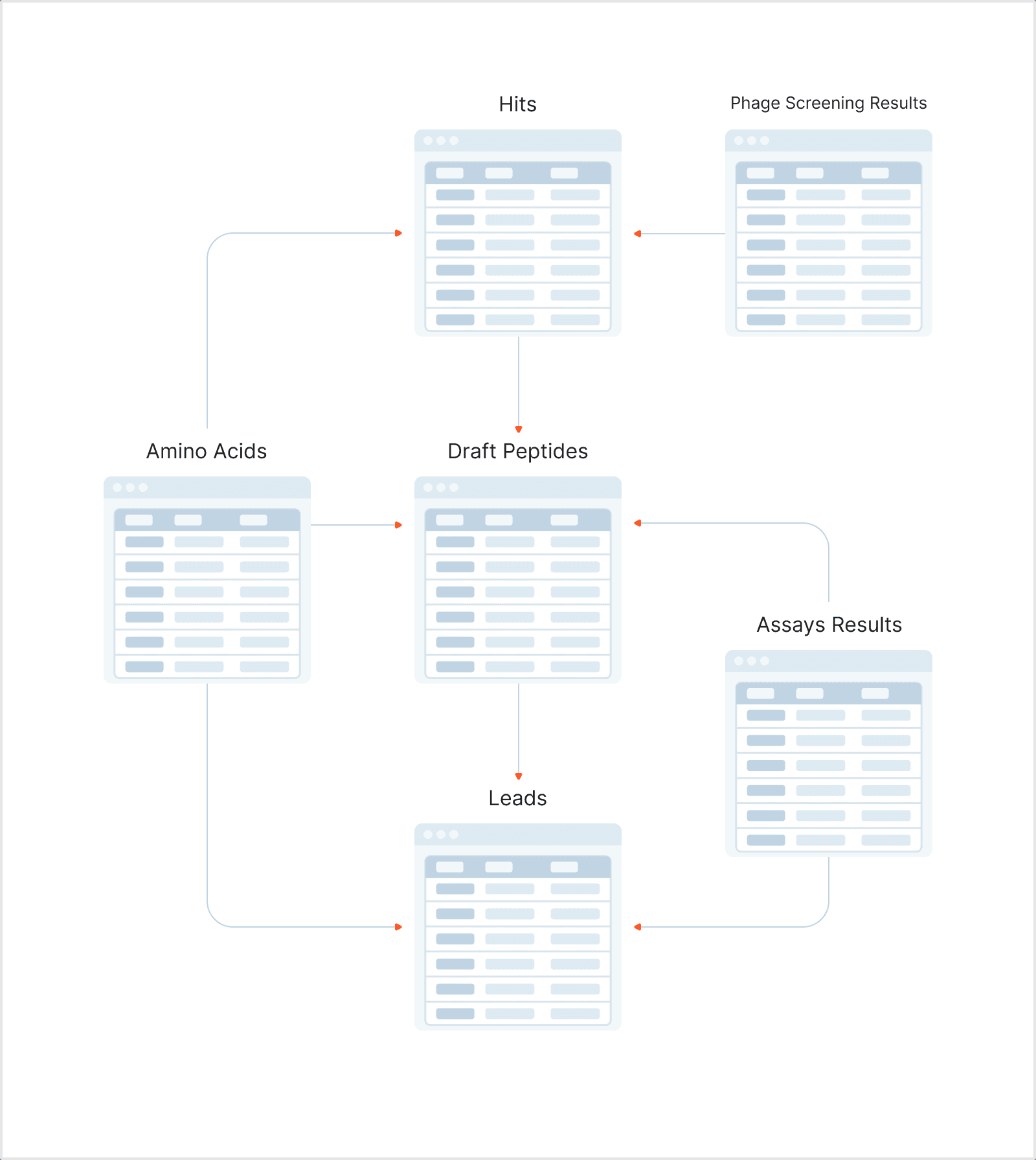
Image 4. Data Centralization
- Controlled Manual Data Entry (Addressing Data Inconsistency and Calculation Issues): To minimize errors during manual data entry, we used dropdown menus and other regulated input methods. Real-time data validation catches errors instantly. The system defines permissible values for fields, regulates data types, and automatically corrects input errors, such as extra spaces. Users receive prompts for incorrect data and can select from suggested options, ensuring early error detection and correction.
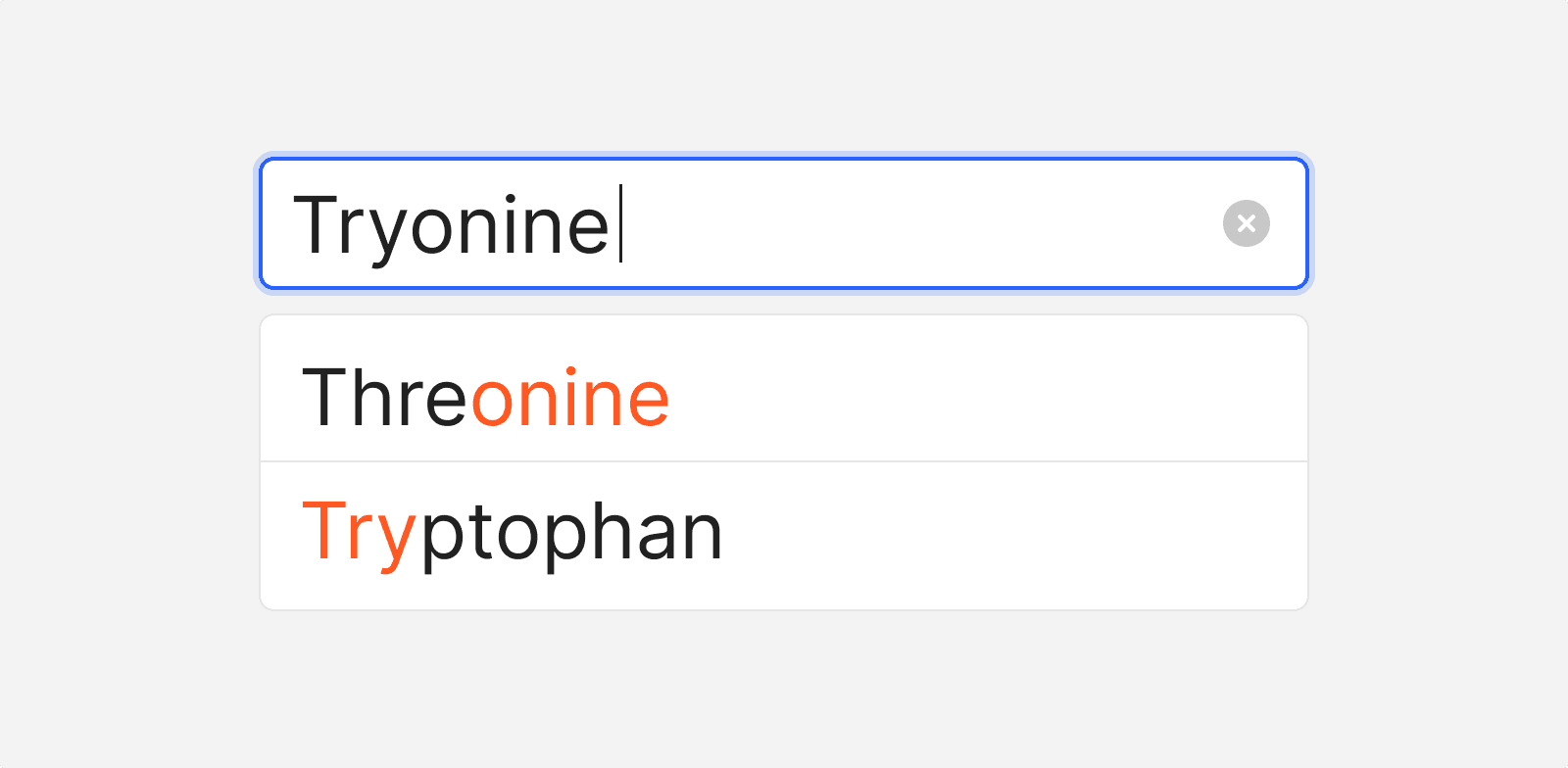
Image 5. Controlled Manual Data Entry
- API Integration (Addressing Fragmented Tools and Data Interoperability): We replaced manual data synchronization with API
— based data exchanges across the client's platforms, ensuring real-time data interoperability. Phage hits and monomers are now updated automatically. - Access Control (Addressing Team Coordination): We implemented role-based access control within the application, allowing different permission levels on the same page. User tracking features were added to monitor activity, identify changes, and pinpoint responsible users, enhancing security and accountability. For example, administrators can allocate peptides to scientists and set permissible values for attributes. Designers can edit peptide molecules and assign attributes from a predefined list, while screeners review the work for errors and inaccuracies
- Specialized Features (Addressing Lack of Custom Features and Team Coordination): The UI focuses on key use cases and removes unnecessary functions. Copy/paste functions are controlled to ensure accurate and precise data transitions, covering entire peptides, previous states, specific structural changes, and associated attributes. The system includes duplicate detection, sequence alignment, complex property calculations, and tracking of peptide lineage. It also supports combinatorial peptide libraries, image formats, peptide notation conversions, and peptide registration.
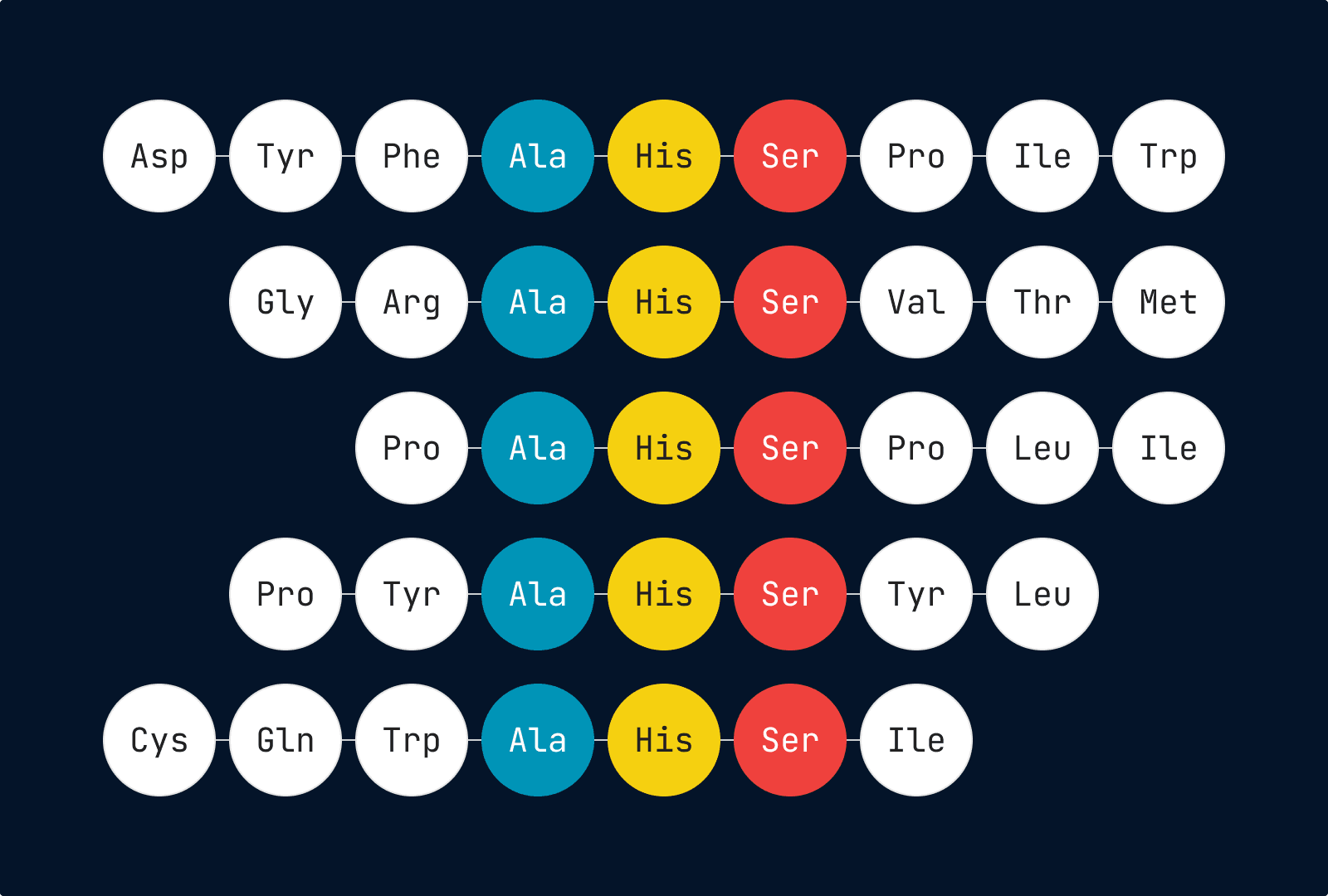
Image 6. Aligned Sequences
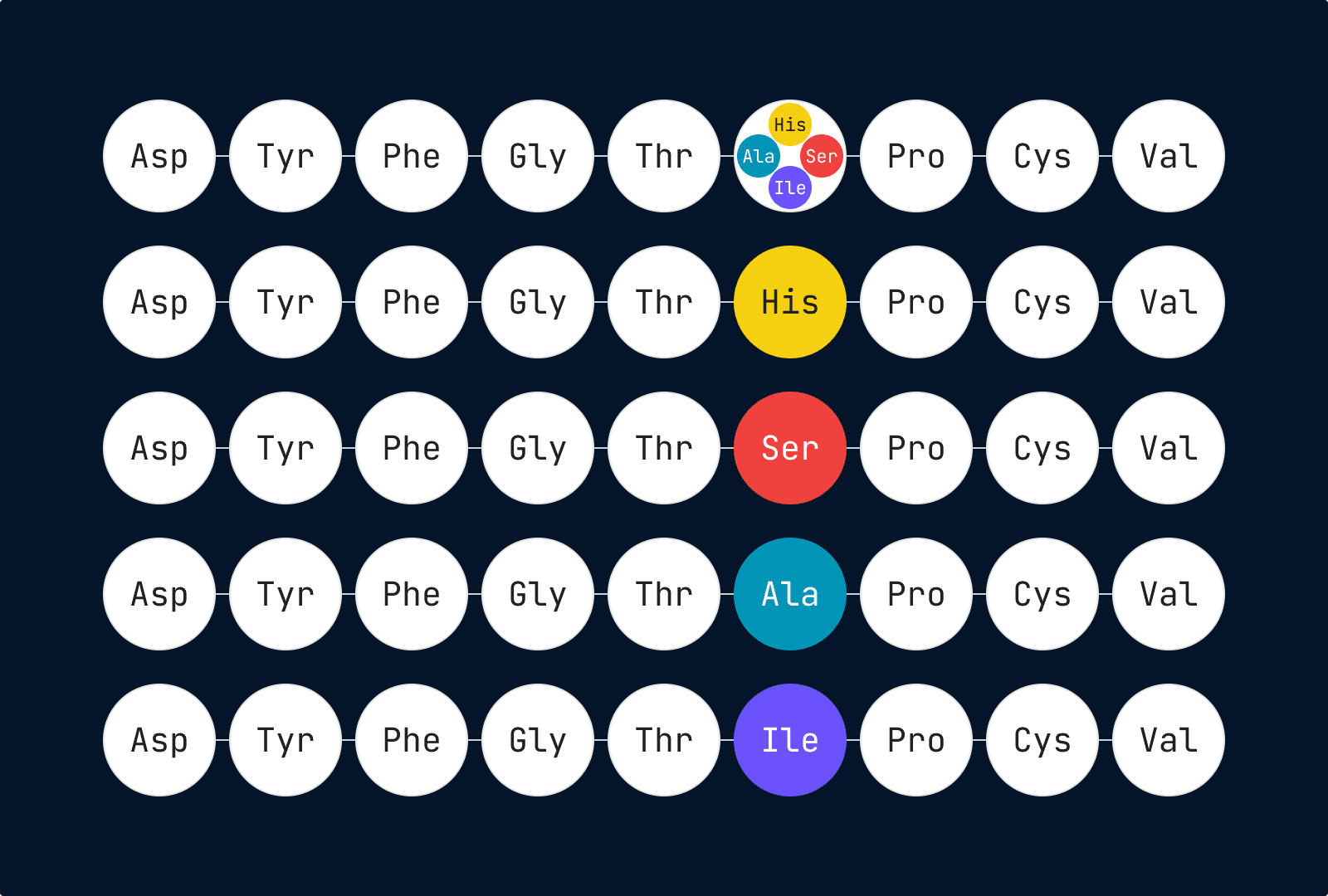
Image 7. Positional scanning combinatorial library
Outcomes and Key Takeaways
The custom peptide drug design system improved data organization, streamlining the entire process and making it easier for scientists to collaborate and analyze results. It facilitated quicker and more precise peptide design, allowing researchers to generate new molecules at twice the speed while increasing scalability to manage growing data needs without disrupting operations. Overall, effective data management and a user-friendly interface led to faster identification of promising peptide leads.