


Machine Learning Strategies for Reliable Microbiome Analysis
Background
Microbiomics is the study of microbial communities and their interactions within specific environments, such as the human gut, soil, or oceans. These microbial communities play essential roles in health, agriculture, and ecosystems. With the advent of high-throughput sequencing technologies, researchers can generate vast amounts of microbiome data. However, analyzing this data is complex due to its high dimensionality and variability, necessitating advanced analytical tools.
ML offers powerful techniques to uncover patterns and insights within microbiome datasets. By applying ML methods, researchers can identify disease biomarkers, predict disease states, and even develop new therapeutics. Companies such as Karius, Viome, and Nexilico are already bringing
Challenges in Applying ML to Microbiomics and Mitigation Strategies
In our recent study, we provided an overview of current practices in applying supervised machine learning to microbiome data. Using a data-driven approach, we guided discussions on the strengths and limitations of different experimental designs and provided recommendations for avoiding common pitfalls that can impact model performance, trustworthiness, and reproducibility. Here, we highlight some of the most significant challenges and strategies to address them.
Dataset size
One of the most significant hurdles in applying ML to microbiome research is the relatively small size of available datasets. ML algorithms typically require large volumes of data to produce robust models, yet microbiome studies often work with limited sample sizes. Our analysis found that 73% of microbiome ML studies had fewer than 1,000 samples, with over a third including fewer than 100 samples. Such small datasets can lead to high variability and poor model generalization, ultimately reducing their reliability in clinical settings. Large-scale data collection efforts, supported by data-sharing initiatives and consortia, will be essential to overcoming this limitation. Researchers may mitigate the detrimental effects of small dataset sizes by applying techniques such as data augmentation and ensuring the use of proper validation practices to minimize bias from small sample sizes.
Demographic bias
Another pressing issue is the lack of demographic diversity in microbiome datasets. Most studies report only basic demographic details, such as country of residence, age, and sex, while factors like race, education level, and income are often missing. This lack of representation can lead to biased models that perform well in one population but poorly in others. For example, studies focusing on Asian populations were found to be 21 times more prevalent than those on African or Oceanian populations, raising concerns about how well these models will generalize across global populations. Ensuring demographic diversity in microbiome research will be critical for developing unbiased and effective
Data leakage and validation issues
A common pitfall in ML applications to microbiomics is test set omission and data
The Importance of Explainability in Microbiome ML Research
Beyond technical challenges, the application of ML in microbiome research also highlights the critical need for explainability. Large-scale studies produce complex models that often function as “black boxes,” obscuring how specific features drive predictions. In clinical and research settings, this lack of transparency can hinder understanding and acceptance of
Looking Ahead
Machine learning has the potential to revolutionize microbiome research, paving the way for new diagnostics, therapeutics, and personalized medicine approaches. However, realizing this potential requires overcoming significant challenges, including small dataset sizes, demographic biases, and methodological inconsistencies. By fostering interdisciplinary collaboration, implementing standardized best practices, and addressing ethical concerns, the microbiome research community can ensure that ML models are robust, fair, and clinically relevant. As data-sharing initiatives expand and computational methods improve,
At Quantori, we create teams of top-tier bioinformaticians, ML engineers, and data scientists to help our clients navigate complex ML model development with efficiency and precision. By adhering to best practices, we save our clients valuable time and resources while delivering robust, reliable solutions. For a deeper dive into the topics covered in this blog, we recommend reading our article, ‘Supervised machine learning for microbiomics: Bridging the gap between current and best practices’.
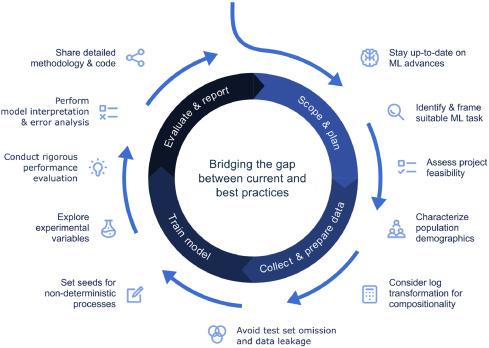
Action items for how scientists can improve current practices in the application of ML to microbiomics data. Source: Dudek et al., 2024, Machine Learning with Applications 18, 100607