


Approaches to Multi-Omics Data Integration
The integrated analysis of multiple omic modalities, such as genomics, transcriptomics, proteomics, metabolomics, epigenomics, and microbiomics, allows scientists to better understand molecular changes between different biological states.
For example, when studying cancer development, combining genomics and metabolomics data can show how gene mutations may correlate with abnormal metabolite production, stimulating tumor growth.
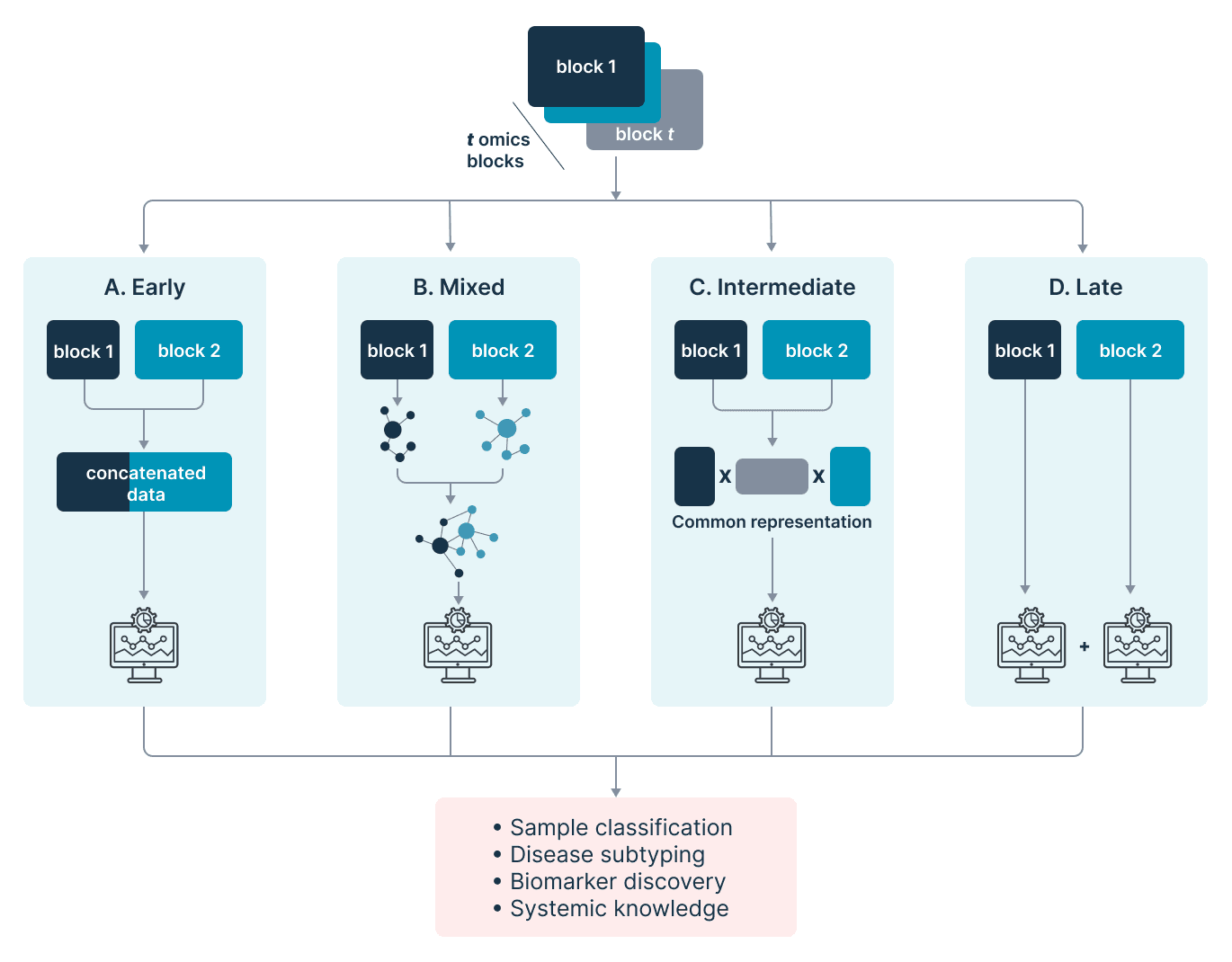
Image Source: Integration strategies of multi-omics data for machine learning analysis
A crucial aspect of multi-omics analysis is integrating data from different omic modalities. Optimal integration empowers multi-omics analysis by aligning the data to underlying assumptions of analytical algorithms. It also captures valuable complementary information between modalities that may amplify salient signals and considers interactions between biomolecules from different omic layers.
For instance, in cancer genetics, combining genomic and transcriptomic data helps match gene expression levels with genetic mutations, providing insights into tumor development.
Multi-omics integration approaches can be loosely categorized by the stage of analysis at which integration is performed. Here, we will focus on early, mixed, intermediate, and late approaches to multi-omics data integration, as defined by Picard et al. (2019).
- Early integration. Datasets from all omics modalities are concatenated into a single, large matrix, often followed by the application of dimensionality reduction techniques. The matrix can then be used for downstream analysis, for example for the development of machine learning (ML) models. This approach is simple, fast, and easy. It allows for a variety of downstream analyses that can reveal interactions between biomolecules from different omics layers.
However, there are several challenges associated with this approach:
a) the concatenated dataset possesses an extraordinary number of unique features, which exacerbates the curse of dimensionality.
b) large differences in the number of features per -omics modality can create a learning imbalance where downstream algorithms prioritize one modality over another.
c) furthermore, distinct and poorly defined data distribution across each modality could violate key assumptions of downstream algorithms and lead to inaccurate or even erroneous. - Mixed integration. Each independent omics data is transformed into a simpler representation before concatenating all representations into a single matrix. Representations can be achieved using techniques such as kernel learning and neural networks (e.g., auto-encoders, graph neural networks, graph convolution networks, restricted Boltzmann machines, etc.).
Intermediate integration offers a powerful approach for combining information from multiple omics modalities while reducing dimensionality within and heterogeneity between omics datasets. However, this approach may require very large sample sizes in some cases, especially when using deep learning techniques. - Intermediate integration. Multi-omics datasets are integrated without prior omics-specific transformation and with more complex techniques than applying a simple concatenation. These methods often assume that different omics modalities can be decomposed into a common latent space, revealing salient mechanisms underlying a biological process.
Methods like non-negative matrix factorization (NMF) and multi-omics factor analysis (MOFA) fall into this category. They tend to be flexible and accommodating of different experimental designs and data inputs, reducing dataset dimensionality and complexity. However, rigorous feature selection and data pre-processing are often required to diminish heterogeneity between datasets and achieve high performance. - Late integration involves analyzing each omics modality separately and then combining the results quantitatively, often through ensemble ML methods such as averaging or majority voting. While this allows one to apply approaches and tools specifically developed for each independent -omics modality, it allows for little to no inference of interactions or complementarities between omics modalities.
Selecting the right data integration method for your multi-omics project lays the foundation for success.
At Quantori, our team of seasoned bioinformatics experts will guide you towards the most effective analysis strategy for your multi-omics project’s unique needs and help implement that vision. Furthermore, our data landscaping team is adept at augmenting dataset sizes, maximizing the potential of your multi-omics dataset.